
Driving treatment decisions on 25 Sep 2015
Cancer models are used by scientists to define and better understand cancer. They describe the rules cancer follows – how it starts, grows, metastasizes, and ultimately how it can be killed. Reviews of their cancer models generate new treatment proposals that the models indicate should be successful.
Cancer models are driving the direction of cancer funding, research, prevention and treatment. Faulty cancer models lead to research producing ineffective treatments. Some researchers say that is happening now.
Cancer Models Example
Let’s look at one example of a simple cancer model. It’s just a picture that describes how a normal cell might progress to a cancer cell and then a tumor. In this model, each time the cell divides, a mistake in the replication process results in a mutation (indicated by the star symbol) in one of the two daughter cells. After enough divisions with accumulated mutations, a cancer tumor cell results (highest cell in the red area). All subsequent daughter cells are cancer cells and additional mutations keep happening. The tumor ends up containing cells with varying kinds of mutations. However, the mutations present in the first tumor cell remain present in all daughter cells. These are called driver mutations1, because they drove the initial cancer and will be present throughout the entire tumor.
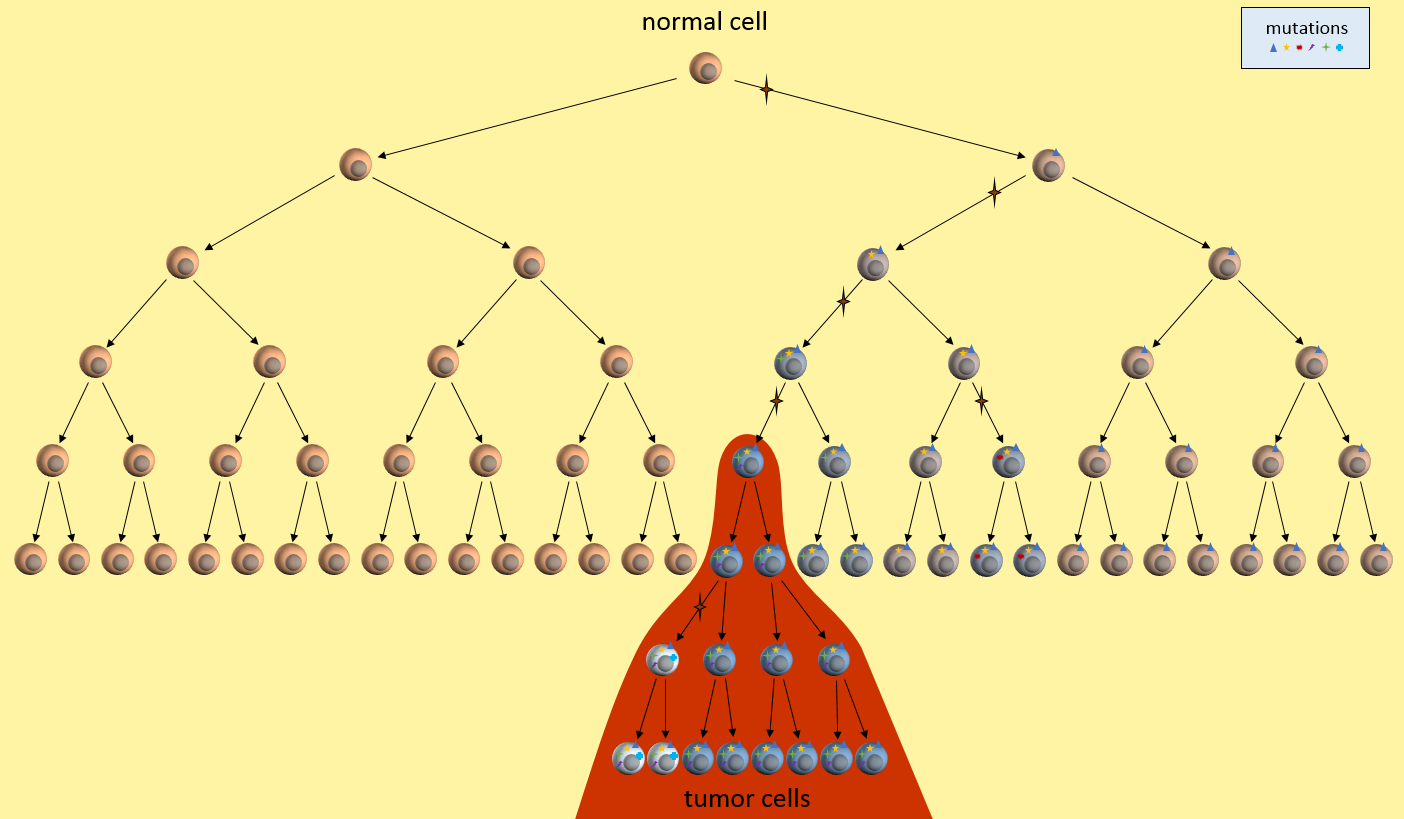
Model of Mutation Accumulation in the Clonal Evolution Model
Let’s just take this simple model, and ask ourselves some questions. What are this model’s weaknesses? What treatment decisions might this model recommend?
Testing the Model
First, let’s look at what our model implies about cancer growth. Does it fit with observations from real-world patients?
Mutations Only During Replication?
What does our model tell us about cancer growth? For instance, is it reasonable that mutations only happen at during replication? Well, we seem to know that cells need about 20-30 mutations before they can become cancerous. We also know that normal cells can only replicate about 40 to 60 times before their telomere length is too short to allow any more replications. Given this, and DNA’s ability to repair itself, we might have to adjust our model to allow more than one mutation per replication, or allow mutations to happen without replication, or grow longer telomeres. We might design experiments to determine which of these is more correct and then update the model to reflect the new findings.
Are There Nearby Pre-Cancerous Cells?
Our model also seems to indicate that there will be many cells nearby with some mutations, but not enough to yet be cancerous, or pre-cancerous. Is this something that a pathologist can determine? Can we separate out nearby normal-looking cells and genetically sequence them to see if they have some mutations but not all?
Timeline Of Cancer Development?
We might observe that our model seems to require quite a few generations of replications before the first cancerous cell develops. Where to all these cells go? What does this tell us about how quickly cancer could develop? What ages cancers might develop? Does this fit in with the childhood leukemia? Does it fit in with pancreatic cancer? Do we need different models for these cancers? Which cancers does it fit?
Cancer models raise many questions like these that drive directions of research that demand funding. Answering these questions allow us to tweak the model to be more accurate. The more accurate the model, the better its predictive power for new treatments.

Cancer Model Development Flowchart
Refining the Model
After we’ve tested the model and experimentally determined new facts, we can update the cancer model. The updated model would be tested again, continually refining the model.
Using the Model
Once we’re happy that the cancer model is mostly reflecting reality and is able to answer basic questions about cancer’s behavior, we are ready to put this model into practical use.
Treatment Decisions
What does our model tell us about treatment decisions? For one, this model seems to indicate that there are certain mutations that will be present in all daughter tumor cells. Examine those nearby pre-cancerous cells. Do they hold the key to uncovering these cancer driver mutations1? If we can find these driver mutations and target them with treatments, we might be able to kill off the entire tumor. This is the idea behind the NIH’s Precision Medicine Initiative.
Tumor Heterogeneity
Our model also says that many mutations will only be present in a part of the tumor – not the entire tumor. See those white and blue cancer cells in the model? They represent tumor cells with different sets of mutations. If we treat only for the white cells’ mutations, the blue cells might continue to grow. This observation fits current patient outcomes.
Early Detection
What does our model say about early detection? Our model indicates that precancerous cells will be around for a while before the cancerous cells develop. It there some way we might be able to detect these pre-cancerous cells? Perhaps they affect the environment around them or put out markers that might be picked up in the bloodstream? This model might drive the development of another model that looks at these issues in the cellular environment.
(Re)-Refining the Model
The cancer model is always being updated to reflect the best knowledge of how cancer works. This simple model really just deals with cancer at a very high level, but even so, it reveals directions for research, early detection, and treatments. Continual refinement of even this simple model brings forth new ideas to be tested, further feeding the models.
Summary
Don’t think that there is some “master” cancer model somewhere that all researchers work from. Each group has its own models developed from their own experience, lab tests, ideas from other groups, etc. These cancer models describe some aspect of cancer as it is understood by the local research team.
In the next posts, I’ll describe two current cancer models. The clonal evolution model2 that has been driving research and funding decisions for several decades. And the cancer stem cell model3 that is not widely accepted but is gaining traction. Which cancer model is (more) correct has a profound effect on patient treatment choices.
Our lack of progress could mean we need to take another look at our basic assumptions, the cancer model, and develop a new model that describes not only how cancer starts, grows, and metastasizes, but also accounts for why we’ve been failing in the “war on cancer”. Each model will undergo continuous revision and tweaking based on new tests to improve their accuracy.
References
[1] Stratton MR (9 April 2009). “The cancer genome”. Nature 485(7239):719-24. PMID: 19360079.
[2] Nowell PC (October 1976). “The clonal evolution of tumor cell populations”. Nature 194(4260):23-8. PMID: 959840.
[3] Soltysova A, Altanerova V, et al. (2005). “Cancer stem cells”. Neoplasma 52(6):435-40. PMID: 16284686.
Oct 2015:
I like it. Do you care for constructive criticism?
Perhaps you should add a “date” to the blog post. This could have been written three years ago, as far as visitors can tell.
Make the “Cancer Model of Mutation Accumulation” graph bigger. The “key” is tiny and the stars (colors) are hard to see, unless you have a giant monitor.
I look forward to the next blog posts.
Thanks for the feedback! I’m not happy with the formatting I’ve chosen by default and maybe now it’s time to update the look.